
aws summit에서 첫 번째로서버리스 기반 SaaS 데이터 처리 및 데이터 웨어하우스 구축 사례'를 들었다
2개의 회사에서 기술적인 issue를 로직 변경 혹은 aws 기능 사용을 통해 해결했다는 내용이다
첫 번째 회사: 애이슬립
AI모델로 수면을 정확하게 분석하여 맞춤형 수면 서비스를 제공하는 Saas 서비스를 제공하는 회사
before
초기 architecture의 3가지 문제점이 있었다고 한다
설명이 전부 기억나지 않아 내 예상을 조합해서 설명한다
-> 요점은 client에서 user가 ui를 이용 시 요청하는 api와 수면 분석의 stream data를 저장하는 요청이 동일한 elb를 통해서 일어나고 아래 이미지와 같은 문제가 발생한다는 점이다

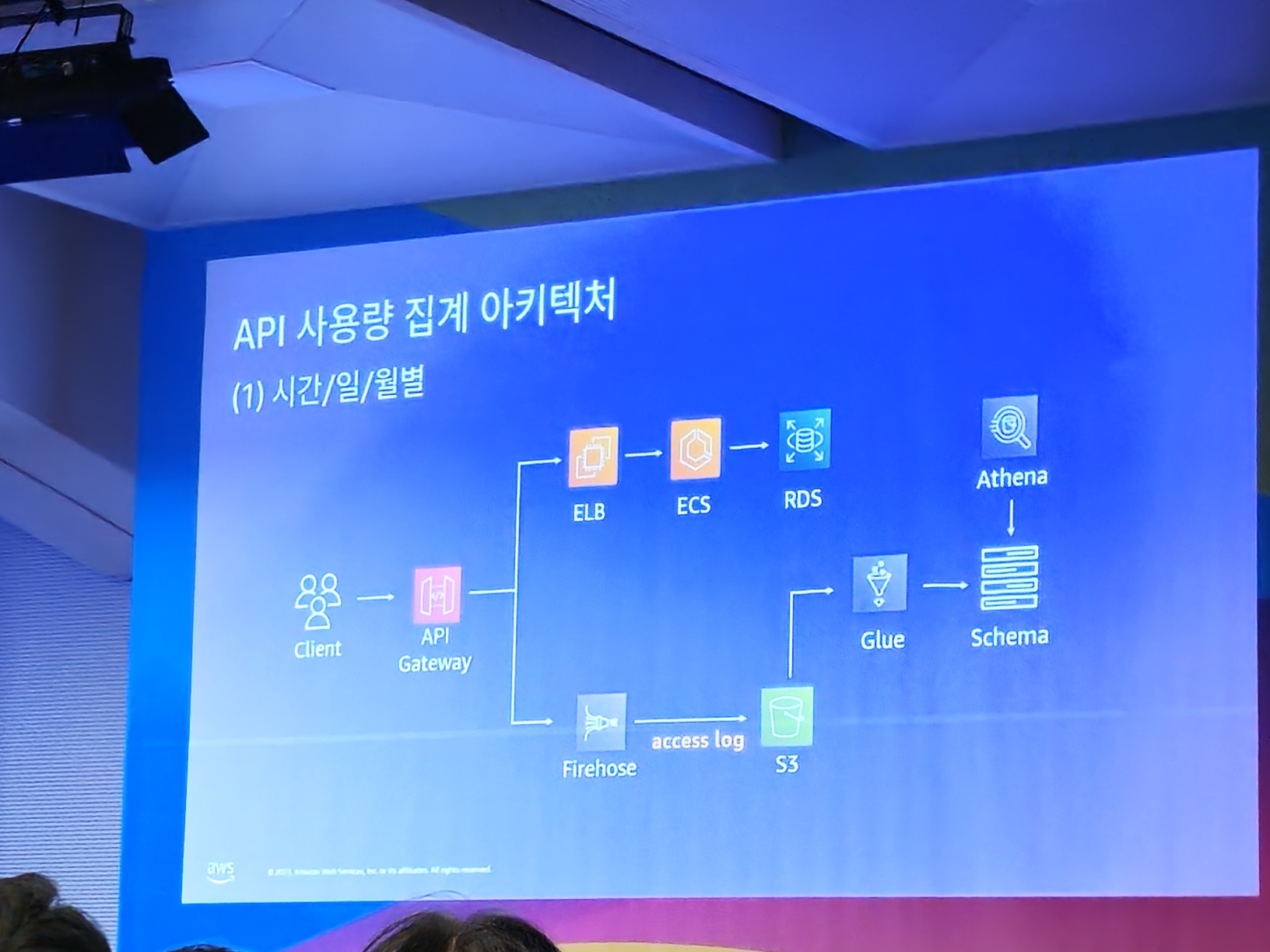
after
설명이 전부 기억나지 않아 내 예상을 조합해서 설명한다
-> gateway를 통해 넘어온 수면분석 stream data를 firehose에 전달하고 data가 쌓이면 통해 s3 bucket에 저장한다
serverless ETL(Extract, Transform, Load)인 aws glue를 통해 비정형 data를 변형하여 dataSource를 저장하는 듯하다
데이터는 parquet type으로 압축하여 저장하는 방식으로 바꿔 더욱 효율적이었다고 한다
dataSource에 주기적인 요청이 필요한 경우 serverless로 query를 하는 aws athena를 사용하는듯하다
aws 쪽 infra는 cdk를 사용해서 관리했다고 한다
before에 비해 금액 감소 및 관리할 일이 감소했다고 한다

두 번째 회사: 매드업
디지털 마케팅 자동화 설루션을 개발 및 운영


대용량 데이터를 수집, 가공해서 데이터웨어하우스 만들고 싶다 했다
Amazon Athena에서 어떻게 Amazon redshift Serverless를 통해 데이터가 필요한 조직에 공급되는지 설명했다
https://aws.amazon.com/ko/blogs/korea/new-aqua-advanced-query-accelerator-for-amazon-redshift/

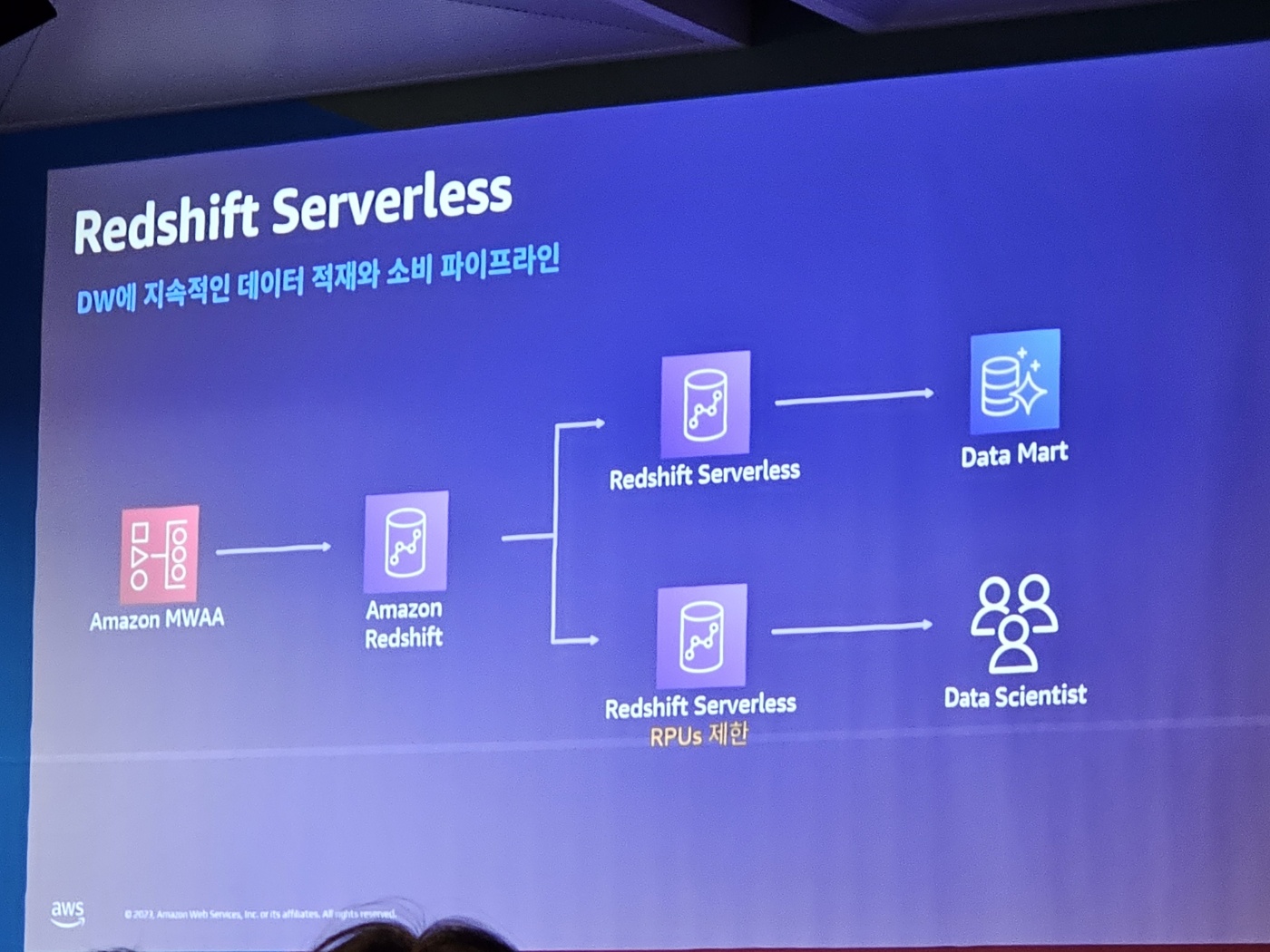
그리고 대용량 데이터를 다루는 부분을 소개했다

여기서 내게 도움이 되었던 점은 serverless의 사용성이다
aws의 glue, athena, redshift가 startUp scene에서 이만큼 사용되었다?
꽤나 효율적이고 데이터 신뢰성이 올라가며 비용이 절감된다는 의미다
aws summit에서 첫 번째로서버리스 기반 SaaS 데이터 처리 및 데이터 웨어하우스 구축 사례'를 들었다
2개의 회사에서 기술적인 issue를 로직 변경 혹은 aws 기능 사용을 통해 해결했다는 내용이다
첫 번째 회사: 애이슬립
AI모델로 수면을 정확하게 분석하여 맞춤형 수면 서비스를 제공하는 Saas 서비스를 제공하는 회사
before
초기 architecture의 3가지 문제점이 있었다고 한다
설명이 전부 기억나지 않아 내 예상을 조합해서 설명한다
-> 요점은 client에서 user가 ui를 이용 시 요청하는 api와 수면 분석의 stream data를 저장하는 요청이 동일한 elb를 통해서 일어나고 아래 이미지와 같은 문제가 발생한다는 점이다
after
설명이 전부 기억나지 않아 내 예상을 조합해서 설명한다
-> gateway를 통해 넘어온 수면분석 stream data를 firehose에 전달하고 data가 쌓이면 통해 s3 bucket에 저장한다
serverless ETL(Extract, Transform, Load)인 aws glue를 통해 비정형 data를 변형하여 dataSource를 저장하는 듯하다
데이터는 parquet type으로 압축하여 저장하는 방식으로 바꿔 더욱 효율적이었다고 한다
dataSource에 주기적인 요청이 필요한 경우 serverless로 query를 하는 aws athena를 사용하는듯하다
aws 쪽 infra는 cdk를 사용해서 관리했다고 한다
before에 비해 금액 감소 및 관리할 일이 감소했다고 한다
두 번째 회사: 매드업
디지털 마케팅 자동화 설루션을 개발 및 운영
대용량 데이터를 수집, 가공해서 데이터웨어하우스 만들고 싶다 했다
Amazon Athena에서 어떻게 Amazon redshift Serverless를 통해 데이터가 필요한 조직에 공급되는지 설명했다
https://aws.amazon.com/ko/blogs/korea/new-aqua-advanced-query-accelerator-for-amazon-redshift/
그리고 대용량 데이터를 다루는 부분을 소개했다
여기서 내게 도움이 되었던 점은 serverless의 사용성이다
aws의 glue, athena, redshift가 startUp scene에서 이만큼 사용되었다?
꽤나 효율적이고 데이터 신뢰성이 올라가며 비용이 절감된다는 의미다